
Define judging criteria first
The technical architecture of your contest platform must follow the evaluation logic, not the other way around. Before writing a single line of code or selecting a database schema, you need to map abstract human judgment into structured digital fields. If the scoring model is vague, no amount of engineering will fix the fairness issues later.
Start by listing every attribute a judge needs to assess. Break these down into weighted categories. For example, a design contest might allocate 40% to aesthetics, 30% to functionality, and 30% to innovation. Each category should map to a specific input field in your system, such as a numeric slider, a text box, or a star rating. This mapping ensures that every entry is measured against the same baseline, preventing judges from drifting into subjective preferences.
Include bias checks directly into the criteria definition. If a category like "originality" is too open-ended, judges may unconsciously favor familiar styles. Add specific sub-criteria or rubrics to narrow the scope. For instance, instead of just "originality," use "novelty of approach" and "uniqueness of execution." This forces judges to evaluate distinct aspects rather than relying on gut feelings.
This initial configuration phase is critical. It determines how data flows through your platform, how results are aggregated, and how disputes are resolved. Take the time to get it right, and the rest of the development process will be significantly smoother.
Configure the scoring workflow
A contest management platform’s fairness depends entirely on how the scoring engine is initialized. Before accepting entries, you must define the judging panel, establish the scoring scale, and configure bias-mitigation rules. This section walks through the technical setup required to ensure blind judging and randomized distribution.

Begin by creating user roles for judges, administrators, and reviewers. Assign specific permissions to ensure judges can only access the scoring interface and not the entry identities. In most platforms, this involves setting up a dedicated "Judge" role with restricted view access to participant data.

Enable blind judging to hide participant names, IDs, and demographic information from the scoring form. This prevents unconscious bias from influencing scores. The system should anonymize entries automatically before they are assigned to judges. Verify that the "Anonymize Entry" toggle is active in the judging configuration panel.

Randomization ensures that no single judge reviews the same set of entries consecutively, reducing fatigue and pattern bias. Configure the platform to shuffle entries for each judge session. This can be done by setting the distribution method to "Random" in the judging workflow settings. The system will then assign entries dynamically as judges log in.

Define the scoring rubric. Decide whether to use a Likert scale (e.g., 1-5), a numeric range, or a weighted criteria system. For example, you might assign 40% weight to "Creativity" and 60% to "Technical Execution." Input these weights into the scoring engine so that the final score is calculated automatically. Ensure that minimum and maximum thresholds are set to flag outlier scores.

Set up automated bias checks to monitor judge performance. The platform should flag judges who consistently give extreme scores (all 1s or all 5s) or who score significantly faster than the average. Configure alerts to notify administrators when these thresholds are breached. This allows for real-time intervention if a judge is not following the rubric.
By following these steps, you create a transparent, auditable, and fair scoring environment. The platform will handle the heavy lifting of randomization and anonymization, allowing judges to focus solely on the quality of the entries.
Test automation against bias
Automating scoring is efficient, but unchecked algorithms can amplify existing prejudices. To build a fair contest management platform, you must treat algorithmic suggestions as starting points, not final verdicts. This section outlines how to configure your system to audit these suggestions and preserve human nuance.
Compare scoring methods
Before configuring your bias checks, understand the trade-offs between fully manual and fully automated systems. The table below compares these approaches across key dimensions relevant to contest fairness.
| Method | Speed | Bias Risk | Transparency |
|---|---|---|---|
| Manual Scoring | Slow | High (unconscious) | Full |
| AI-Assisted Scoring | Fast | Medium (algorithmic) | Partial |
| Hybrid Review | Medium | Low (audited) | High |
Configure scoring weights
Define explicit weights for each judging criterion in your platform’s configuration. Avoid defaulting to uniform weights, as this often masks the relative importance of specific skills or attributes. For example, in a design contest, weight "originality" at 40% and "technical execution" at 60%. Document these weights publicly to ensure transparency for participants.
Audit algorithmic suggestions
Implement a review step where human judges can override or adjust AI-generated scores. Log every override to identify patterns. If the AI consistently scores entries from a specific demographic lower, this signals a bias in your training data or feature selection. Use these logs to retrain your model or adjust the weighting parameters.
Preserve human nuance
Algorithms struggle with subjective qualities like "emotional impact" or "cultural relevance." Ensure your platform’s interface allows judges to add qualitative comments alongside numerical scores. This data is crucial for explaining decisions to participants and for future model audits. By keeping humans in the loop, you maintain the integrity of the contest.
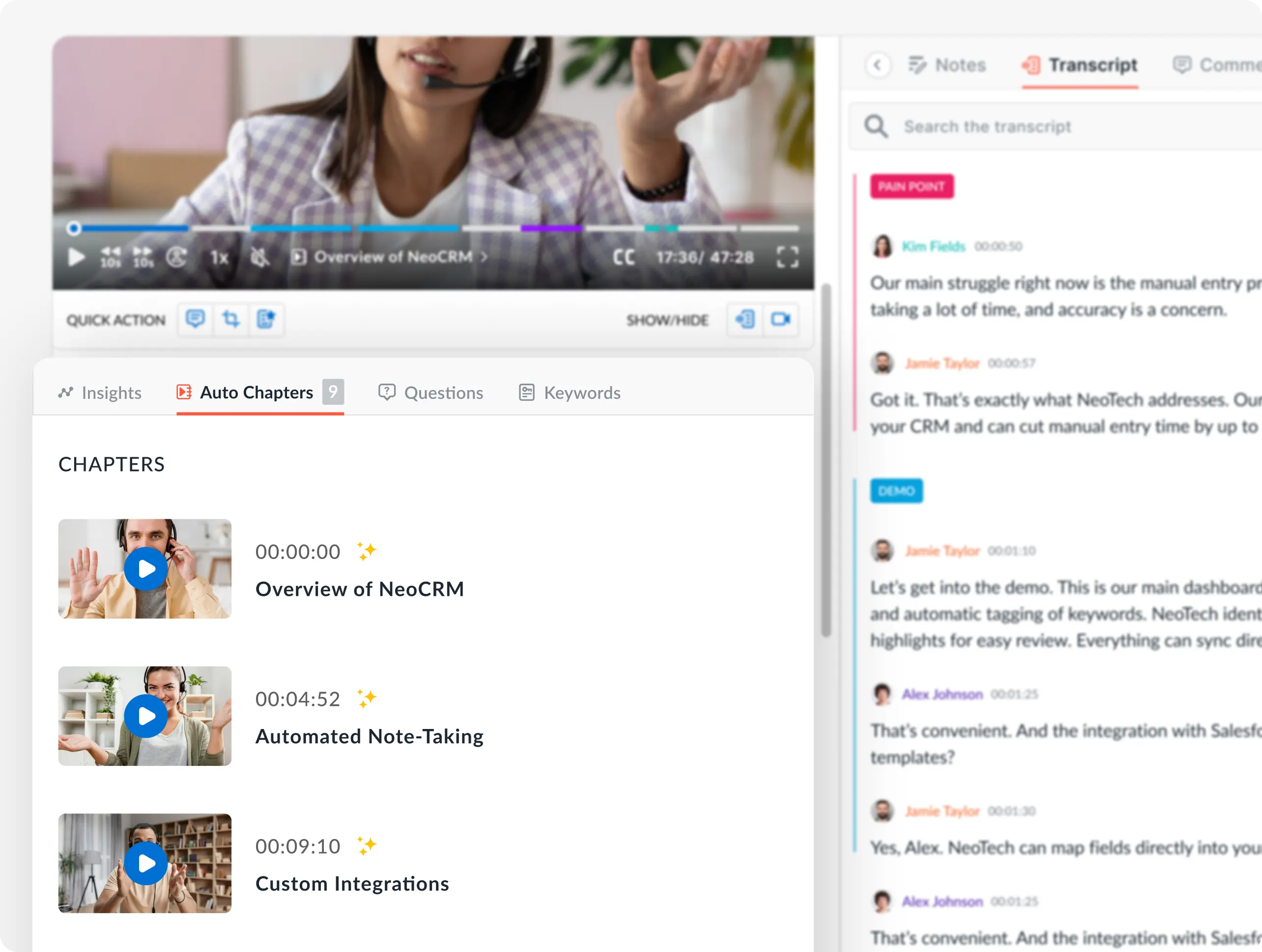
Train judges on the interface
Technical setup fails without human adoption. Even the most sophisticated scoring algorithms cannot compensate for judges who do not understand the platform's workflow. Training must move beyond simple login instructions to cover calibration, bias mitigation, and the specific mechanics of the scoring interface.
Start by ensuring judges can plan around the dashboard without friction. Require them to complete a sandbox run-through using dummy entries. This step verifies that their browsers are compatible and that they understand how to submit scores, add comments, and flag conflicts. A judge who struggles with the interface will either abandon the contest or submit inconsistent data.
Calibration is the next critical step. Judges must understand how scoring weights function. For example, if "originality" counts for 40% and "technical execution" for 60%, judges need to see how these weights impact the final rank. Use concrete examples to demonstrate how a high score in one category might not outweigh a low score in another. This prevents "halo effects" where a single strong attribute skews the entire evaluation.
Bias checks should be integrated into the training module. Show judges how to identify and mitigate unconscious bias. For instance, if the platform anonymizes entries, explain why this matters and how the system preserves anonymity. If bias detection algorithms are active, briefly explain how they flag outliers. This transparency builds trust in the fairness of the system.
Finally, require a certification step before judges are activated. This ensures that every participant has confirmed their understanding of the rules and the interface. Without this gate, you risk having untrained judges influence the outcome, undermining the integrity of the entire contest.

Verify results before publication
Before making the final rankings public, you must audit the output to ensure it aligns with your configured fairness criteria. This verification step catches calculation errors, bias anomalies, and edge cases that automated systems might miss.
Export and inspect raw data
Begin by exporting the raw scoring data from your platform’s admin dashboard. Look for statistical outliers in the judge submissions. If a specific judge’s scores deviate significantly from the group mean, investigate whether their scoring rubric was misconfigured or if they are applying inconsistent standards.
Check for scoring bias
Run a bias check against demographic or categorical metadata if available. Ensure that no specific category or group is systematically receiving higher or lower scores than others due to algorithmic weighting errors. For example, if your weights favor "creativity" over "technicality," verify that the final rankings reflect this balance accurately across all entries.
Confirm final ranking logic
Cross-reference the automated ranking list with your manual adjustments. If you allow judges to override scores, ensure those overrides are logged and justified. The final published list must match the exact sorting algorithm defined in your contest rules, preventing last-minute discrepancies that could undermine trust.
Common questions about judging software
When building a fair contest management platform, technical configuration often raises specific operational questions. The following sections address how to handle data privacy, enforce judge anonymity, and resolve scoring ties automatically.
No comments yet. Be the first to share your thoughts!